martes, 8 de octubre de 2013
Nociones de probalidad
La probabilidad es un método mediante el cual se obtiene la frecuencia de un suceso determinado mediante la realización de un experimento aleatorio, del que se conocen todos los resultados posibles, bajo condiciones suficientemente estables. La teoría de la probabilidad se usa extensamente en áreas como la estadística, la física, la matemática, las ciencias y la filosofía para sacar conclusiones sobre la probabilidad discreta de sucesos potenciales y la mecánica subyacente discreta de sistemas complejos.
Las probabilidades constituyen una rama de las matemáticas que se ocupa de medir o determinar cuantitativamente la posibilidad de que un suceso o experimento produzca un determinado resultado.
Historia
El diccionario de la Real Academia Española define «azar» como una casualidad, un caso fortuito, y afirma que la expresión «al azar» significa «sin orden».1 La idea de Probabilidad está íntimamente ligada a la idea de azar y nos ayuda a comprender nuestras posibilidades de ganar un juego de azar o analizar las encuestas. Pierre-Simon Laplace afirmó: "Es notable que una ciencia que comenzó con consideraciones sobre juegos de azar haya llegado a ser el objeto más importante del conocimiento humano". Comprender y estudiar el azar es indispensable, porque la probabilidad es un soporte necesario para tomar decisiones en cualquier ámbito.2
Según Amanda Dure, "Antes de la mitad del siglo XVII, el término 'probable' (en latín probable) significaba aprobable, y se aplicaba en ese sentido, unívocamente, a la opinión y a la acción. Una acción u opinión probable era una que las personas sensatas emprenderían o mantendrían, en las circunstancias."3
Aparte de algunas consideraciones elementales hechas por Girolamo Cardano en el siglo XVI, la doctrina de las probabilidades data de la correspondencia de Pierre de Fermat y Blaise Pascal(1654). Christiaan Huygens (1657) le dio el tratamiento científico conocido más temprano al concepto. Ars Conjectandi (póstumo, 1713) de Jakob Bernoulli y Doctrine of Chances (1718) deAbraham de Moivre trataron el tema como una rama de las matemáticas. Véase El surgimiento de la probabilidad (The Emergence of Probability) de Ian Hacking para una historia de los inicios del desarrollo del propio concepto de probabilidad matemática.
La teoría de errores puede trazarse atrás en el tiempo hasta Opera Miscellanea (póstumo, 1722) de Roger Cotes, pero una memoria preparada por Thomas Simpson en 1755 (impresa en 1756) aplicó por primera vez la teoría para la discusión de errores de observación. La reimpresión (1757) de esta memoria expone los axiomas de que los errores positivos y negativos son igualmente probables, y que hay ciertos límites asignables dentro de los cuales se supone que caen todos los errores; se discuten los errores continuos y se da una curva de la probabilidad.
Pierre-Simon Laplace (1774) hizo el primer intento para deducir una regla para la combinación de observaciones a partir de los principios de la teoría de las probabilidades. Representó la ley de la probabilidad de error con una curva  , siendo
, siendo  cualquier error e y
cualquier error e y  su probabilidad, y expuso tres propiedades de esta curva:
su probabilidad, y expuso tres propiedades de esta curva:
, siendo cualquier error e y su probabilidad, y expuso tres propiedades de esta curva:- es simétrica al eje ;
- el eje es una asíntota, siendo la probabilidad del error
 igual a 0;
igual a 0; - la superficie cerrada es 1, haciendo cierta la existencia de un error.
Dedujo una fórmula para la media de tres observaciones. También obtuvo (1781) una fórmula para la ley de facilidad de error (un término debido a Lagrange, 1774), pero una que llevaba a ecuaciones inmanejables. Daniel Bernoulli (1778) introdujo el principio del máximo producto de las probabilidades de un sistema de errores concurrentes.
El método de mínimos cuadrados se debe a Adrien-Marie Legendre (1805), que lo introdujo en su Nouvelles méthodes pour la détermination des orbites des comètes (Nuevos métodos para la determinación de las órbitas de los cometas). Ignorando la contribución de Legendre, un escritor irlandés estadounidense, Robert Adrain, editor de "The Analyst" (1808), dedujo por primera vez la ley de facilidad de error,

siendo  y
y 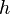 constantes que dependen de la precisión de la observación. Expuso dos demostraciones, siendo la segunda esencialmente la misma de John Herschel (1850). Gauss expuso la primera demostración que parece que se conoció en Europa (la tercera después de la de Adrain) en 1809. Demostraciones adicionales se expusieron por Laplace (1810, 1812), Gauss (1823),James Ivory (1825, 1826), Hagen (1837), Friedrich Bessel (1838), W. F. Donkin (1844, 1856) y Morgan Crofton (1870). Otros personajes que contribuyeron fueron Ellis (1844), De Morgan (1864),Glaisher (1872) y Giovanni Schiaparelli (1875). La fórmula de Peters (1856) para
constantes que dependen de la precisión de la observación. Expuso dos demostraciones, siendo la segunda esencialmente la misma de John Herschel (1850). Gauss expuso la primera demostración que parece que se conoció en Europa (la tercera después de la de Adrain) en 1809. Demostraciones adicionales se expusieron por Laplace (1810, 1812), Gauss (1823),James Ivory (1825, 1826), Hagen (1837), Friedrich Bessel (1838), W. F. Donkin (1844, 1856) y Morgan Crofton (1870). Otros personajes que contribuyeron fueron Ellis (1844), De Morgan (1864),Glaisher (1872) y Giovanni Schiaparelli (1875). La fórmula de Peters (1856) para  , el error probable de una única observación, es bien conocida.
, el error probable de una única observación, es bien conocida.
y constantes que dependen de la precisión de la observación. Expuso dos demostraciones, siendo la segunda esencialmente la misma de John Herschel (1850). Gauss expuso la primera demostración que parece que se conoció en Europa (la tercera después de la de Adrain) en 1809. Demostraciones adicionales se expusieron por Laplace (1810, 1812), Gauss (1823),James Ivory (1825, 1826), Hagen (1837), Friedrich Bessel (1838), W. F. Donkin (1844, 1856) y Morgan Crofton (1870). Otros personajes que contribuyeron fueron Ellis (1844), De Morgan (1864),Glaisher (1872) y Giovanni Schiaparelli (1875). La fórmula de Peters (1856) para , el error probable de una única observación, es bien conocida.
En el siglo XIX, los autores de la teoría general incluían a Laplace, Sylvestre Lacroix (1816), Littrow (1833), Adolphe Quetelet (1853), Richard Dedekind (1860), Helmert (1872), Hermann Laurent(1873), Liagre, Didion, y Karl Pearson. Augustus De Morgan y George Boole mejoraron la exposición de la teoría.
En 1930 Andréi Kolmogorov desarrolló la base axiomática de la probabilidad utilizando teoría de la medida.
En la parte geométrica (véase geometría integral) los colaboradores de The Educational Times fueron influyentes (Miller, Crofton, McColl, Wolstenholme, Watson y Artemas Martin).
Véase también: Estadística.
Teoría
La probabilidad constituye un importante parámetro en la determinación de las diversas casualidades obtenidas tras una serie de eventos esperados dentro de un rango estadístico.
Existen diversas formas como método abstracto, como la teoría Dempster-Shafer y la teoría de la relatividad numérica, esta última con un alto grado de aceptación si se toma en cuenta que disminuye considerablemente las posibilidades hasta un nivel mínimo ya que somete a todas las antiguas reglas a una simple ley de relatividad.[cita requerida]
La probabilidad de un evento se denota con la letra p y se expresa en términos de una fracción y no en porcentajes, por lo que el valor de p cae entre 0 y 1. Por otra parte, la probabilidad de que un evento "no ocurra" equivale a 1 menos el valor de p y se denota con la letra q

Los tres métodos para calcular las probabilidades son la regla de la adición, la regla de la multiplicación y la distribución binomial.
Regla de la adición
La regla de la adición o regla de la suma establece que la probabilidad de ocurrencia de cualquier evento en particular es igual a la suma de las probabilidades individuales, si es que los eventos son mutuamente excluyentes, es decir, que dos no pueden ocurrir al mismo tiempo.
P(A o B) = P(A) U P(B) = P(A) + P(B) si A y B son mutuamente excluyente. P(A o B) = P(A) + P(B) − P(A y B) si A y B son no excluyentes.
Siendo: P(A) = probabilidad de ocurrencia del evento A. P(B) = probabilidad de ocurrencia del evento B. P(A y B) = probabilidad de ocurrencia simultánea de los eventos A y B.
Regla de la multiplicació
La regla de la multiplicación establece que la probabilidad de ocurrencia de dos o más eventos estadísticamente independientes es igual al producto de sus probabilidades individuales.
P(A y B) = P(A B) = P(A)P(B) si A y B son independientes. P(A y B) = P(A B) = P(A)P(B|A) si A y B son dependientes
Regla de Laplace
La regla de Laplace establece que:
- La probabilidad de ocurrencia de un suceso imposible es 0.
- La probabilidad de ocurrencia de un suceso seguro es 1, es decir, P(A) = 1.
Para aplicar la regla de Laplace es necesario que los experimentos den lugar a sucesos equiprobables, es decir, que todos tengan o posean la misma probabilidad.
- La probabilidad de que ocurra un suceso se calcula así:
P(A) = Nº de casos favorables / Nº de resultados posibles
Esto significa que: la probabilidad del evento A es igual al cociente del número de casos favorables (los casos dónde sucede A) sobre el total de casos posibles.
Distribución binomial
La probabilidad de ocurrencia de una combinación específica de eventos independientes y mutuamente excluyentes se determina con la distribución binomial, que es aquella donde hay solo dos posibilidades, tales como masculino/femenino o si/no.
- Hay dos resultados posibles mutuamente excluyentes en cada ensayo u observación.
- La serie de ensayos u observaciones constituyen eventos independientes.
- La probabilidad de éxito permanece constante de ensayo a ensayo, es decir el proceso es estacionario.
Para aplicar esta distribución al cálculo de la probabilidad de obtener un número dado de éxitos en una serie de experimentos en un proceso de Bermnoulli, se requieren tres valores: el número designado de éxitos (m), el número de ensayos y observaciones (n); y la probabilidad de éxito en cada ensayo (p).
Entonces la probabilidad de que ocurran m éxitos en un experimento de n ensayos es:
P (x = m) = (nCm)(Pm)(1−P)n−m
Siendo: nCm el número total de combinaciones posibles de m elementos en un conjunto de n elementos.
En otras palabras P(x = m) = [n!/(m!(n−m)!)](pm)(1−p)n−m
Entonces la probabilidad de que ocurran m éxitos en un experimento de n ensayos es:
P (x = m) = (nCm)(Pm)(1−P)n−m
Siendo: nCm el número total de combinaciones posibles de m elementos en un conjunto de n elementos.
En otras palabras P(x = m) = [n!/(m!(n−m)!)](pm)(1−p)n−m
Ejemplo. La probabilidad de que un alumno apruebe la asignatura Cálculo de Probabilidades es de 0,15. Si en un semestre intensivo se inscriben 15 alumnos ¿Cuál es la probabilidad de que aprueben 10 de ellos?
P(x = 10) = 15C10(0,15)10(0,85)5 = 10!/(10!(15−10)!)(0,15)10(0,85)5 = 7,68 * 10−6 Generalmente existe un interés en la probabilidad acumulada de "m o más " éxitos o "m o menos" éxitos en n ensayos. En tal caso debemos tomar en cuenta que:
P(x < m) = P(x = 0) + P(x = 1) + P(x = 2) + P(x = 3) +....+ P(x = m − 1)
P(x > m) = P(x = m+ 1) + P(x = m+ 2) + P(x = m+3) +....+ P(x = n)
P(x ≤ m) = P(x = 0) + P(x = 1) + P(x = 2) + P(x = 3) +....+ P(x = m)
P(x ≥ m) = P(x = m) + P(x = m+1) + P(x = m+2) +....+ P(x = n)
Supongamos que del ejemplo anterior se desea saber la probabilidad de que aprueben:
a.− al menos 5
b.− más de 12
a.− la probabilidad de que aprueben al menos 5 es:
P(x ≥ 5) es decir, que:
1 - P(x < 5) = 1 - [P(x = 0)+P(x = 1)+P(x = 2)+P(x = 3)+P(x = 4)] =
1 - [0,0874 + 0,2312 + 0,2856 + 0,2184 + 0,1156] = 0,0618
Nota: Al menos, a lo menos y por lo menos son locuciones adverbiales sinónimas.
P(x = 10) = 15C10(0,15)10(0,85)5 = 10!/(10!(15−10)!)(0,15)10(0,85)5 = 7,68 * 10−6 Generalmente existe un interés en la probabilidad acumulada de "m o más " éxitos o "m o menos" éxitos en n ensayos. En tal caso debemos tomar en cuenta que:
P(x < m) = P(x = 0) + P(x = 1) + P(x = 2) + P(x = 3) +....+ P(x = m − 1)
P(x > m) = P(x = m+ 1) + P(x = m+ 2) + P(x = m+3) +....+ P(x = n)
P(x ≤ m) = P(x = 0) + P(x = 1) + P(x = 2) + P(x = 3) +....+ P(x = m)
P(x ≥ m) = P(x = m) + P(x = m+1) + P(x = m+2) +....+ P(x = n)
Supongamos que del ejemplo anterior se desea saber la probabilidad de que aprueben:
a.− al menos 5
b.− más de 12
a.− la probabilidad de que aprueben al menos 5 es:
P(x ≥ 5) es decir, que:
1 - P(x < 5) = 1 - [P(x = 0)+P(x = 1)+P(x = 2)+P(x = 3)+P(x = 4)] =
1 - [0,0874 + 0,2312 + 0,2856 + 0,2184 + 0,1156] = 0,0618
Nota: Al menos, a lo menos y por lo menos son locuciones adverbiales sinónimas.
Ejemplo: La entrada al cine por lo menos tendrá un costo de 10 soles (como mínimo podría costar 10 soles o más).
b.− la probabilidad de que aprueben más de 12 es P(x > 12) es decir, que:
P(x > 12) = P(x = 13)+P(x = 14)+P(x = 15)
P(x > 12) = 1,47 *10−9 +3,722 *10−11 +4,38 *10−13 = 1,507 *10−9
La esperanza matemática en una distribución binomial puede expresarse como:
E(x) = np = 15(0,15)=2,25
Y la varianza del número esperado de éxitos se puede calcular directamente:
Var(x) = np(1−p)= 15(0,15)(1-0,15)=1,9125 Estadísticas y probabilidades, con sus diferentes diagramaciones como: diagrama de barras. diagrama de línea. y diagrama de círculos que se aplican de acuerdo al tipo de estadísticas y probabilidades matemáticas.
b.− la probabilidad de que aprueben más de 12 es P(x > 12) es decir, que:
P(x > 12) = P(x = 13)+P(x = 14)+P(x = 15)
P(x > 12) = 1,47 *10−9 +3,722 *10−11 +4,38 *10−13 = 1,507 *10−9
La esperanza matemática en una distribución binomial puede expresarse como:
E(x) = np = 15(0,15)=2,25
Y la varianza del número esperado de éxitos se puede calcular directamente:
Var(x) = np(1−p)= 15(0,15)(1-0,15)=1,9125 Estadísticas y probabilidades, con sus diferentes diagramaciones como: diagrama de barras. diagrama de línea. y diagrama de círculos que se aplican de acuerdo al tipo de estadísticas y probabilidades matemáticas.
Aplicaciones
Dos aplicaciones principales de la teoría de la probabilidad en el día a día son en el análisis de riesgo y en el comercio de los mercados de materias primas. Los gobiernos normalmente aplican métodos probabilísticos en regulación ambiental donde se les llama "análisis de vías de dispersión", y a menudo miden el bienestar usando métodos que son estocásticos por naturaleza, y escogen qué proyectos emprender basándose en análisis estadísticos de su probable efecto en la población como un conjunto. No es correcto decir que la estadística está incluida en el propio modelado, ya que típicamente los análisis de riesgo son para una única vez y por lo tanto requieren más modelos de probabilidad fundamentales, por ej. "la probabilidad de otro 11-S". Una ley de números pequeños tiende a aplicarse a todas aquellas elecciones y percepciones del efecto de estas elecciones, lo que hace de las medidas probabilísticas un tema político.
Un buen ejemplo es el efecto de la probabilidad percibida de cualquier conflicto generalizado sobre los precios del petróleo en Oriente Medio - que producen un efecto dominó en la economía en conjunto. Un cálculo por un mercado de materias primas en que la guerra es más probable en contra de menos probable probablemente envía los precios hacia arriba o hacia abajo e indica a otros comerciantes esa opinión. Por consiguiente, las probabilidades no se calculan independientemente y tampoco son necesariamente muy racionales. La teoría de las finanzas conductualessurgió para describir el efecto de este pensamiento de grupo en el precio, en la política, y en la paz y en los conflictos.
Se puede decir razonablemente que el descubrimiento de métodos rigurosos para calcular y combinar los cálculos de probabilidad ha tenido un profundo efecto en la sociedad moderna. Por consiguiente, puede ser de alguna importancia para la mayoría de los ciudadanos entender cómo se calculan los pronósticos y las probabilidades, y cómo contribuyen a la reputación y a las decisiones, especialmente en una democracia.
Otra aplicación significativa de la teoría de la probabilidad en el día a día es en la fiabilidad. Muchos bienes de consumo, como los automóviles y la electrónica de consumo, utilizan la teoría de la fiabilidad en el diseño del producto para reducir la probabilidad de avería. La probabilidad de avería también está estrechamente relacionada con la garantía del producto.
Se puede decir que no existe una cosa llamada probabilidad. También se puede decir que la probabilidad es la medida de nuestro grado de incertidumbre, o esto es, el grado de nuestra ignorancia dada una situación. Por consiguiente, puede haber una probabilidad de 1 entre 52 de que la primera carta en un baraja sea la J de diamantes. Sin embargo, si uno mira la primera carta y la reemplaza, entonces la probabilidad es o bien 100% ó 0%, y la elección correcta puede ser hecha con precisión por el que ve la carta. La física moderna proporciona ejemplos importantes de situaciones determinísticas donde sólo la descripción probabilística es factible debido a información incompleta y la complejidad de un sistema así como ejemplos de fenómenos realmente aleatorios.
En un universo determinista, basado en los conceptos newtonianos, no hay probabilidad si se conocen todas las condiciones. En el caso de una ruleta, si la fuerza de la mano y el periodo de esta fuerza es conocido, entonces el número donde la bola parará será seguro. Naturalmente, esto también supone el conocimiento de la inercia y la fricción de la ruleta, el peso, lisura y redondez de la bola, las variaciones en la velocidad de la mano durante el movimiento y así sucesivamente. Una descripción probabilística puede entonces ser más práctica que la mecánica newtoniana para analizar el modelo de las salidas de lanzamientos repetidos de la ruleta. Los físicos se encuentran con la misma situación en la teoría cinética de los gases, donde el sistema determinístico en principio, es tan complejo (con el número de moléculas típicamente del orden de magnitud de la constante de Avogadro  ) que sólo la descripción estadística de sus propiedades es viable.
) que sólo la descripción estadística de sus propiedades es viable.
) que sólo la descripción estadística de sus propiedades es viable.
La mecánica cuántica, debido al principio de indeterminación de Heisenberg, sólo puede ser descrita actualmente a través de distribuciones de probabilidad, lo que le da una gran importancia a las descripciones probabilísticas. Algunos científicos hablan de la expulsión del paraíso.[cita requerida] Otros no se conforman con la pérdida del determinismo. Albert Einstein comentóestupendamente en una carta a Max Born: Jedenfalls bin ich überzeugt, daß der Alte nicht würfelt. (Estoy convencido de que Dios no tira el dado). No obstante hoy en día no existe un medio mejor para describir la física cuántica si no es a través de la teoría de la probabilidad. Mucha gente hoy en día confunde el hecho de que la mecánica cuántica se describe a través de distribuciones de probabilidad con la suposición de que es por ello un proceso aleatorio, cuando la mecánica cuántica es probabilística no por el hecho de que siga procesos aleatorios sino por el hecho de no poder determinar con precisión sus parámetros fundamentales, lo que imposibilita la creación de un sistema de ecuaciones determinista.
Investigación biomédica
La mayoría de las investigaciones biomédicas utilizan muestras de probabilidad, es decir, aquellas que el investigador pueda especificar la probabilidad de cualquier elemento en la población que investiga. Las muestras de probabilidad permiten usar estadísticas inferenciales, aquellas que permiten hacer inferencias a partir de datos. Por otra parte, las muestras no probabilísticas solo permiten usarse estadísticas descriptivas, aquellas que solo permiten describir, organizar y resumir datos. Se utilizan cuatro tipos de muestras probabilísticas: muestras aleatorias simples, muestras aleatorias estratificadas, muestra por conglomerados y muestras sistemáticas.

Nociones de probabilidad(vídeo)
Presentación de nociones de probabilidad
Mapa mental de nociones de probabilidad

sábado, 5 de octubre de 2013
Tabulación y graficación
Tabulación se refiere al hecho de calcular valores parciales para una función y compararlos en una tabla, de ahí el nombre de tabular.
Ejemplo
sea f(x)=2x




Ejemplo
sea f(x)=2x
Ya hemos visto como los modelos matemáticos nos ayudan a resolver desde los problemas más simples, hasta los problemas más complejos, también hemos visto que la complejidad o simplicidad de un modelo es el producto del trabajo intelectual y el estilo de resolver las cosas según la persona que lo aborda, sin embargo, todos buscan lo mismo al final del día, resolver un problema o buscar atender una necesidad.
Para atender el tema de tabular y graficar una función pensemos en una necesidad según el siguiente caso práctico:
El profesor responsable de las actividades de Protección Civil de ha solicitado a ti y a un conjunto de tus compañeros que pintes un círculo en el centro del patio para ahí colocar el punto de encuentro que es requerido como parte del proyecto de protección civil de la escuela.
Necesitas saber dos cosas para cumplir esta asignación.
- Conocer el diámetro del círculo en base al radio que te solicitan tenga el círculo para que sea los suficiente mente grande y de esta forma que todos lo vean.
- Saber los metros cuadrados de área para saber la cantidad de pintura que se necesita comprar (no es lo mismo pagar un cuarto de pintura, dos litros o veinte litros).
Sabemos desde la primaria que calcular el área de un círculo se realiza mediante la siguiente fórmula:
Donde el valor de la variable “A” dependerá del valor que tenga la variable “r” que describe al radio elevado al cuadrado y multiplicado por la constante π. Y que el diámetro del círculo se calcula al multiplicar por dos el valor del radio descrito por “r”
Pongamos esta fórmula en el contexto de una función que describe el área del círculo:
Donde x al igual que en la fórmula original representará el valor del radio.
Ahora vamos a tabular los resultados, esto significa obtener el valor numérico de la función al reemplazar posibles valores de x. Esta actividad es la misma que aprendiste cuando estudiamos el valor numérico de expresiones en la Unidad 1, sección 1-7.
Vamos a emplear herramientas más modernas, usemos Excel para obtener una tabla más completa y detallada haciendo incrementos más pequeños (del orden de 0.1) y que nuestra gráfica sea más exacta. Al momento de solicitar a Excel que ponga en el plano cartesiano los valores del área que obtuvimos nos queda una gráfica del siguiente tipo:
Tabulación y graficación (Vídeo)
Presentación de tabulación y graficación
Ecuaciones cuadráticas
Una ecuación de segundo grado1 2 o ecuación cuadrática de una variable es una ecuación que tiene la forma de una suma algebraica de términos cuyo grado máximo es dos, es decir, una ecuación cuadrática puede ser representada por unpolinomio de segundo grado o polinomio cuadrático. La expresión canónica general de una ecuación cuadrática de una variable es:

donde x representa la variable y a, b y c son constantes; a es un coeficientecuadrático (distinto de 0), b el coeficiente lineal y c es el término independiente. Este polinomio se puede representar mediante una gráfica de una función cuadrática oparábola. Esta representación gráfica es útil, porque la intersección de esta gráfica con el eje horizontal coinciden con las soluciones de la ecuación (y dado que pueden existir dos, una o ninguna intersección, esos pueden ser los números de soluciones de la ecuación).
Historia
El origen y la solución de las ecuaciones de segundo grado son de gran antigüedad. En Babilonia se conocieron algoritmos para resolverla. El resultado también fue encontrado independientemente en otros lugares del mundo. En Grecia, el matemático Diofanto de Alejandría aportó un procedimiento para resolver este tipo de ecuaciones (aunque su método sólo proporcionaba una de las soluciones, aun en el caso de que las dos soluciones sean positivas). También el matemático judeoespañol Abraham bar Hiyya, en su Liber embadorum, discute la solución de estas ecuaciones.
Fórmula cuadrática
Para una ecuación cuadrática con coeficientes reales o complejos existen siempre dos soluciones, no necesariamente distintas, llamadas raíces, que pueden ser reales o complejas (si los coeficientes son reales y existen dos soluciones no reales, entonces deben ser complejas conjugadas). Se denomina fórmula cuadrática3 a la ecuación que proporciona las raíces de la ecuación cuadrática:

donde el símbolo ± indica que los valores
 y
y 
constituyen las dos soluciones.
Discriminante
 Ejemplo del signo del discriminante:
Ejemplo del signo del discriminante:■ < 0: no posee soluciones reales;
■ = 0: posee una solución real (multiplicidad 2);
■ > 0: posee dos soluciones reales distintas.
En la fórmula anterior, la expresión dentro de la raíz cuadrada recibe el nombre dediscriminante de la ecuación cuadrática. Suele representarse con la letra D o bien con el símbolo Δ (delta):

Una ecuación cuadrática con coeficientes reales tiene o bien dos soluciones reales distintas o una sola solución real de multiplicidad 2, o bien dos raíces complejas. El discriminante determina la índole y la cantidad de raíces.
Dos soluciones reales y diferentes si el discriminante es positivo (la parábola cruza dos veces el eje de las abscisas: X):
 .
.Una solución real doble si el discriminante es cero (la parábola sólo toca en un punto al eje de las abscisas: X):
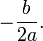
Dos números complejos conjugados si el discriminante es negativo (la parábola no corta al eje de las abscisas: X):
 donde i es la unidad imaginaria.
donde i es la unidad imaginaria.En conclusión, las raíces son distintas si el discriminante es no nulo, y son números reales si –sólo si– el discriminante es no negativo.
Ecuación bicuadrática
Éstas son un caso particular de la ecuación de cuarto grado. Les faltan los términos a la tercera y a la primera potencia. Su forma polinómica es:

Para resolver estas ecuaciones tan solo hay que hacer el cambio de variable

Con lo que nos queda:
 El resultado resulta ser una ecuación de segundo grado que podemos resolver usando la fórmula:
El resultado resulta ser una ecuación de segundo grado que podemos resolver usando la fórmula:
Ahora bien, esto no nos da las cuatro soluciones esperadas. Aún hemos de deshacer el cambio de variable. Así las cuatro soluciones serán:


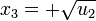


Ecuaciones cuadráticas (Vídeo)
Presentación de ecuaciones cuadráticas
http://www.slideshare.net/lacienciamatematica/01-ecuaciones-cuadrticas
Mapa mental de ecuaciones cuadráticas

Coclusión:
Este tema fue el mas
complicado para mi ya que en segundo grado no aprendi nada en mate pues no
teníamos profe, pero aun asi sabia interpretarlas bueno solo las ecuaciones de
primer grado ya que en las otras se me complicaba, para mi lo mas difícil no
fue resolverlas si no encontrar las ecuaciones, se me dificultaban eso
problemas donde teníamos que encontrar la ecuación correspondiente para
solucionar el problema, pero a fin de cuentas ya puedo dominarlo un poquito
mas, espero poder aprender mas de este tema que es complicado para mi.
Triángulos y cuadriláteros
Un triángulo, en geometría, es un polígono determinado por tres segmentos que se cortan dos a dos en tres puntos (que no se encuentran alineados, es decir: no colineales). Los puntos de intersección de las rectas son los vértices y los segmentos de recta determinados son los lados del triángulo. Dos lados contiguos forman uno de los ángulos interiores del triángulo.
Por lo tanto, un triángulo tiene 3 ángulos interiores, 3 ángulos exteriores, 3 lados y 3 vértices.
Si está contenido en una superficie plana se denomina triángulo, o trígono, un nombre menos común para este tipo de polígonos. Si está contenido en una superficie esférica se denomina triángulo esférico. Representado, en cartografía, sobre la superficie terrestre, se llama triángulo geodésico.

Un cuadrilátero es un polígono que tiene cuatro lados. Los cuadriláteros pueden tener distintas formas, pero todos ellos tienen cuatro vértices y dos diagonales, y la suma de sus ángulos internos siempre da como resultado 360º.
Por lógica todos los cuadriláteros son cuadrángulos, ya que esta definición se aplica a lospolígonos de cuatro ángulos.

Triángulos y cuadriláteros (Video)
Triángulos y cuadriláteros (Power point)
Mapa mental de triángulos y cuadriláteros

Conclusón:
Este tema fue algo
complicado, no mucho pero si algo, el chiste del tema es saber usar tu compas,
transportador o media luna y la regla, pues todos estos instrumentos ayudaban
con el trazo de los triángulos y cuadriláteros, teníamos que aprender la congruencia
de estos para hacerlos muy bien, también tuvimos que aprender los nombres de
los cuadriláteros y de los triángulos por ejemplo saber cual era un romboide o
saber si era un triángulo equilátero, etc. Se que si uno pone de su parte para
aprender del tema no se hara complicado.
Suscribirse a:
Comentarios (Atom)